За кулисами PIM
🖋️ Пишет Хотьян Георгий, начальник отдела разработки бэк-офис систем
PIM, или Product Information Management, это система управления контентом. Покупатели каждый день просматривают на сайте Детского мира несколько миллионов товаров. Ежедневно десятки тысяч из них требуют изменений — создаются новые, снимаются с публикации старые, актуализируется и уточняется информация, меняются изображения и видео. Над этим трудится много наших партнёров, и всё происходит в системе управления контентом — PIM.
Сразу стоит также оговориться, что наши пользователи — это партнёры Детского мира, сторонние продавцы, которые с помощью PIM размещают и непрерывно актуализируют информацию о своих товарах.

Одно из главных требований к системе — она должна иметь приятный и понятный интерфейс. Поскольку именно от интерфейса зависит то, насколько удобно будет пользователю. Если неудобно, если на простые действия уходит много времени, то вырастут издержки для поставщиков и упадёт их заинтересованность в сотрудничестве с нами.
Также в PIM должно одновременно работать множество потоков обмена данными:
- из PIM на сайт, где карточки товаров видят покупатели,
- в PIM из маркетплейс-площадки, где поставщики наполняют карточки,
- между PIM и складской системой SAP, которую используют в офлайн-магазинах.
Основной момент, из-за которого мы решили создать PIM, это динамическое управление атрибутами в зависимости от категорий, в которых находятся товары. Например, если в какой-то момент среди производителей детских колясок станет популярным оборудовать их мультимедийной системой с возможностью проигрывания колыбельных, то наша система PIM позволит добавить этот атрибут в раздел «Коляски» за несколько секунд.
После, конечно, потребуется заполнить конкретные модели. Но основная работа будет сделана легко и достаточно быстро. Впрочем, процесс наполнения данными тоже довольно прост: PIM позволяет выгрузить информацию о колясках отдельной таблицей, заполнить в этой таблице нужное поле для соответствующих моделей и загрузить таблицу обратно.
После этого карточки товаров обновляются на сайте, а пользователи не только видят обновление, но и получают новый фильтр — показать только коляски с той самой мультимедиа-системой. Кроме того, при желании можно составить список только тех моделей, которые есть в ближайшем магазине. Все эти нововведения появляются на сайте быстро и без участия разработчиков.
У нас уже есть статья с подробностями о внутреннем устройстве нашего PIM. Здесь расскажем о процессе, в основу которого легли Jira и Kanban.
Подробнее о Kanban
Хоть у нас и единый процесс, но для удобства мы завели в Jira две kanban-доски.
На первой представлен цикл так называемого анализа. Он начинается в момент формулирования бизнес-цели. Причём, мы стараемся делать так, чтобы это была действительно та цель, которую можно будет ощутить, увидеть после завершения работы над задачей. Задач, результат которых не очевиден, и которые не несут бизнес-ценности, мы стараемся избегать.
Это не значит, что мы не сделаем ничего, что важно с технической точки зрения и что сложно обосновать бизнес-заказчику. Такими задачами мы тоже занимаемся. Просто такой подход учит даже нас самих не ставить задачи как «Добавить в проект таблицу products» или «Добавить в базу данных представление, хранящее количество товаров в категории». Вместо этого мы формулируем задачи, несущие бизнес-ценность: «Пользователь должен видеть список товаров» и «Пользователь видит в списке категорий колонку с количеством привязанных к ним товаров».
Уже в процессе выполнения этих двух бизнес-задач появятся и таблица products, и представление со счётчиком товаров, всё с бэкендом и фронтендом. Но это уже будет способом решения чего-то более ценного и точно нужного. И об этом — чуть ниже.
Пока же эти задачи находятся в стадии «Анализ требований», в дело вступает второй из наших принципов — декомпозирование, таким образом, чтобы скорее поставлять небольшие, но полезные улучшения.
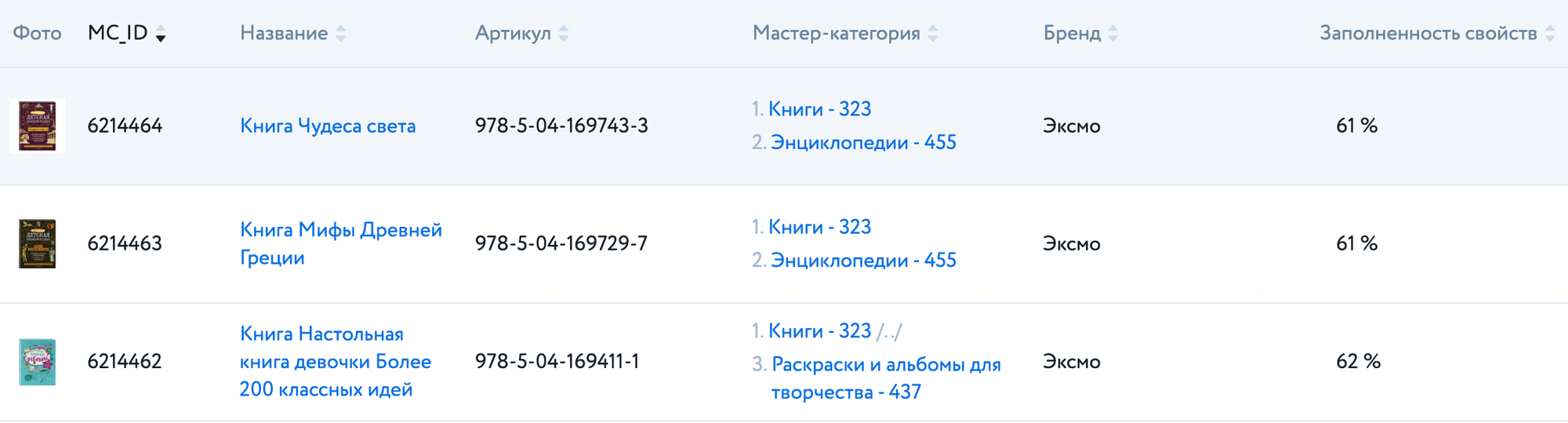
Например, в этом случае будет логично реализовать сперва список без колонок «Фото», «Мастер-категория» и «Заполненность свойств». И сделать это тремя отдельными задачами. Кстати, таким образом задача про список товаров трансформируется в Эпик, который содержит в себе эти задачи, именуемые как Истории, или Story.
Итак, каждая из этих задач попадает в статус «Анализ требований», а после — в «Дизайн».

После дизайна, или когда дизайн не требуется, задача переходит в колонку «Требования готовы». Список задач, попавших сюда, приоритизируется. Самые срочные попадают на «Груминг».
Груминг — это один из ключевых этапов в жизненном цикле нашей разработки. Раз в неделю проходит встреча, на которой очень детально разбираются задачи, которые нужно взять в работу. В этот момент нужно не просто взять задачу с готовыми требованиями и передвинуть её в статус «Готова к разработке», а убедиться, что всем разработчикам и тестировщикам ясны требования. Более того, здесь мы вкратце прописываем, что нужно сделать в стадии бэкенд- и фронтенд-разработки. А также убеждаемся в том, что нам понятны критерии тестирования.
Как уже было сказано, задача представляет собой отдельную пользовательскую историю. А поскольку пользовательская история в большинстве случаев подразумевает доработки бэкенда и фронтенда, задача не делится на две, а вместо этого проходит по отдельным статусам — сначала backend dev, а затем frontend dev. Благодаря такой «неделимости», не нужно организовывать два параллельных стрима и тратить силы на их синхронизацию. Такой подход облегчает ещё и тестирование.

Также на груминге оценивается, сколько задач можно взять на будущую неделю, чтобы загрузка была адекватно полной. Такой подход несёт много плюсов. Процесс становится удобным для всех членов команды. Получается, что в любой момент у разработчика есть некоторое количество понятных, разобранных на груминге задач, которые он может брать в работу. При этом не нужно тратить время на уточнение требований. Если эти задачи достаточно хорошо декомпозированы, то у тестировщика тоже будет постоянный поток. Процесс становится плавным и предсказуемым. Предсказуемость, в свою очередь, позволяет строить метрики, которые сыграли важную роль в процессе работы над PIM.
Анализ метрик
Для анализа мы используем специальный инструмент Nave. Он представляет собой плагин к Jira, который помогает визуализировать и анализировать данные проекта.
В нём есть довольно много полезных графиков и диаграмм. Например, по той, что на рисунке ниже (Cycle Time Scatterplot), можно наглядно оценить вариативность времени выполнения. Здесь горизонтальная ось представляет последовательность задач, а вертикальная — время, затраченное на выполнение каждой задачи.
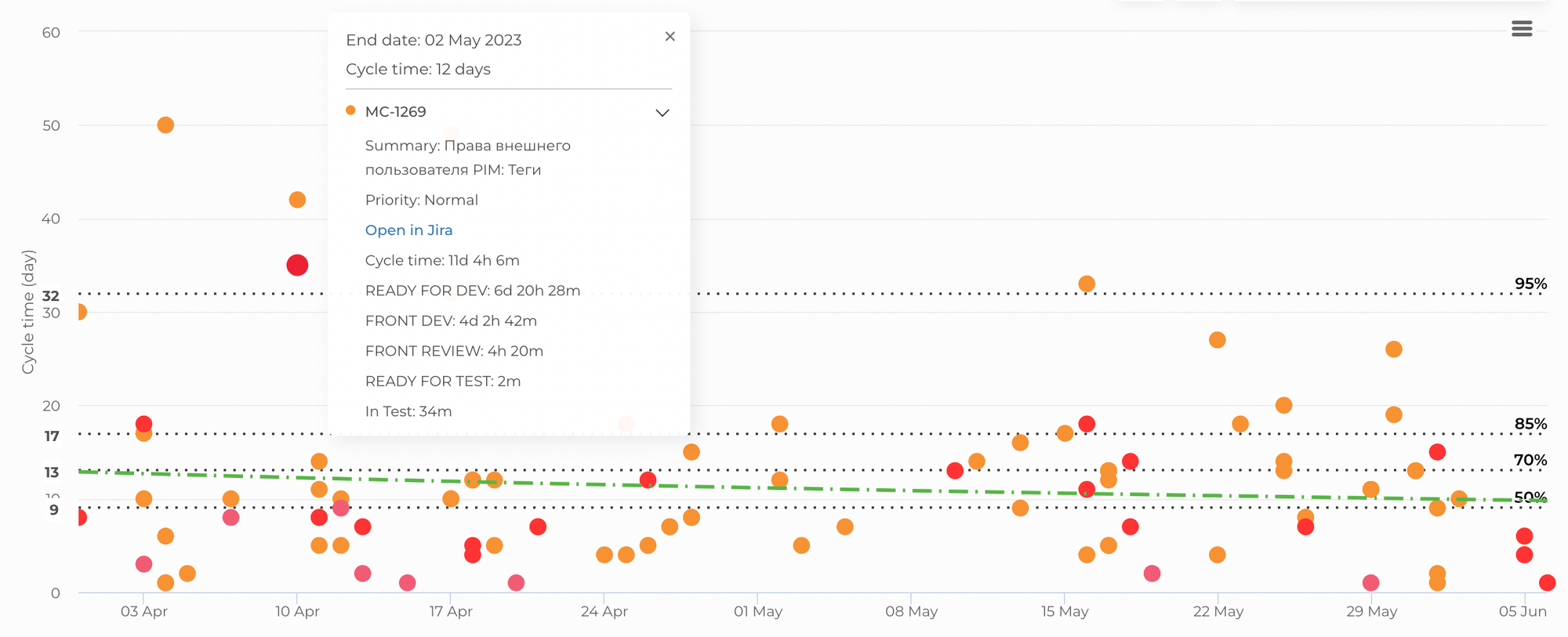
Диаграмма позволяет обнаружить задачи, которые отклоняются от графика. Подробности, доступные здесь же по каждой задаче, помогают понять причины такого их поведения.
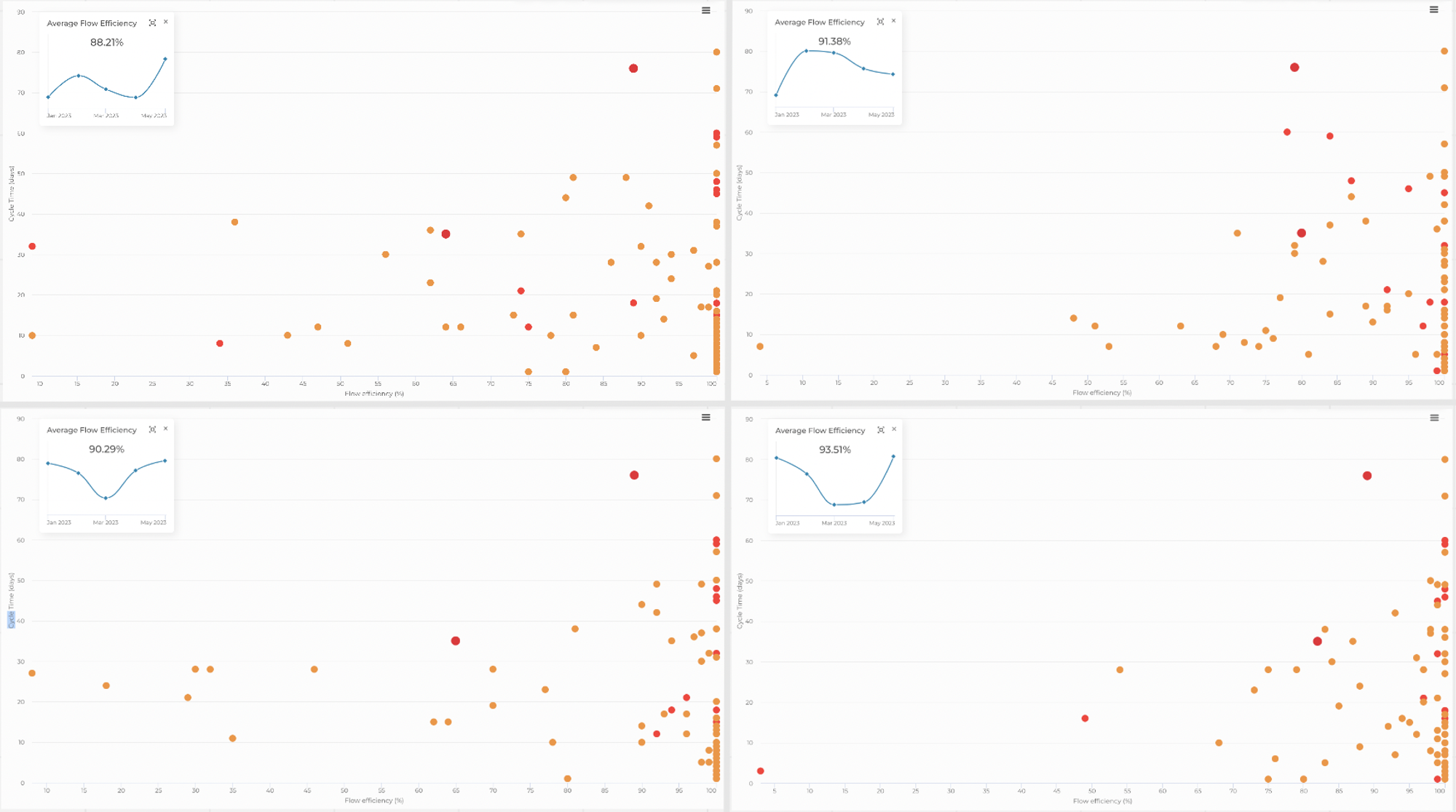
Flow Efficiency Chart — ещё одна диаграмма, похожая на предыдущую, также позволяет оценить, насколько эффективно задачи движутся по статусам. Здесь уже проверяется каждый этап в отдельности. Ниже отдельно визуализируются стадии, в которых задачи ожидают момента перехода в разработку, в тестирование или проведения code review.
Оценивается время, которое задача проводит в ожидании на этих четырёх этапах, для большего удобства эффективность показана в процентном соотношении, а также в виде графика. Когда у задач появляются хронические сложности с переходом на следующий этап, эффективность будет падать. Если что-то пойдёт не так, то здесь будет уже совсем просто определить, на каких конкретных этапах возникают задержки.
Всё это помогает нам нормализовать процесс и делать его максимально предсказуемым. И теперь о том, что даёт эта предсказуемость.
Убедившись, что процесс приведён в упорядоченное состояние и отклонения во времени выполнения задач от общего тренда редки, мы можем переходить к прогнозированию сроков выполнения. В Nave для этого есть ещё одна удобная диаграмма, принцип построения которой основан на методе Монте-Карло. При её построении учитываются те же данные о скорости выполнения задач, которые можно было наблюдать на предыдущей. Поэтому, чем более ровный и предсказуемый наш процесс, тем выше точность прогнозирования.
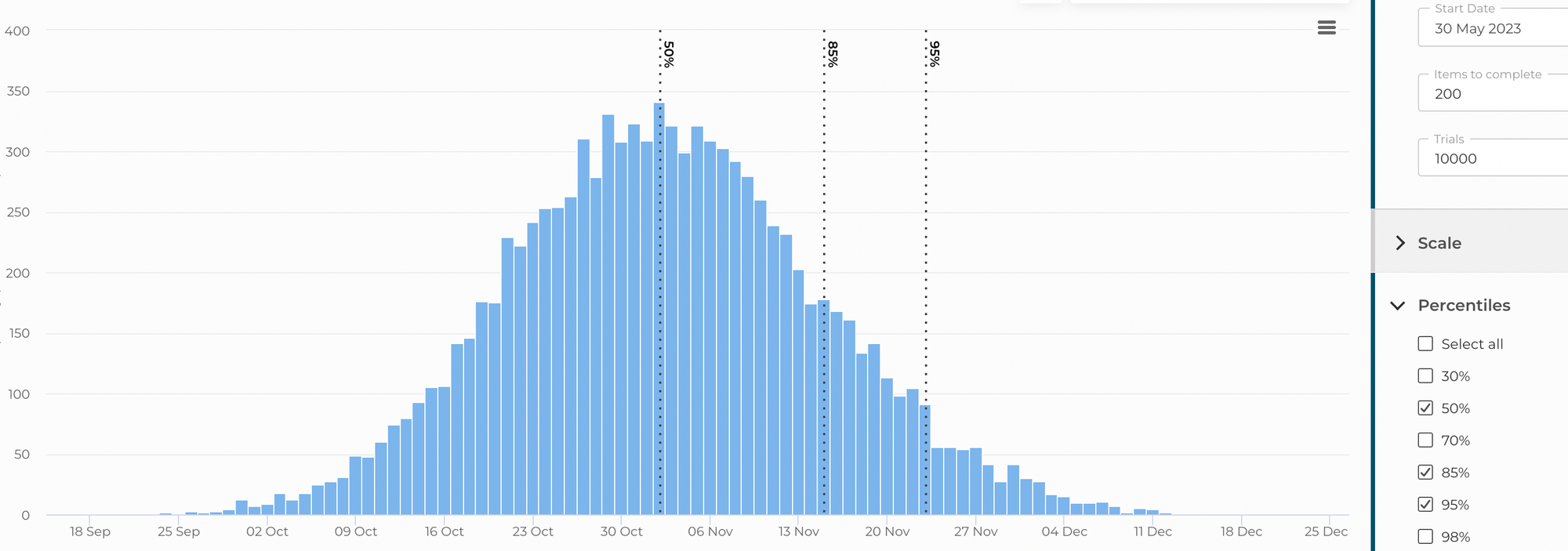
Итак, накопив статистику за три месяца при плавном процессе, и имея к тому времени подробный, разложенный на отдельные пользовательские истории объём работ, мы провели оценку по методу Монте-Карло. В результате получили то количество историй, которые с вероятностью 95 % успевали сделать к определённой дате.
Предстояло успеть внедрить наш новый PIM к началу ноября, так как в этом месяце стартуют основные распродажи, включая «Чёрную пятницу», которые плавно перетекают в высокий сезон предновогодней активности покупателей. На этот период обычно приходится высокая активность в работе с контентом. Остановки, которые повлекло бы переключение со старой системы управления контентом на PIM, в этот период были неизбежны, но и невозможны. Поэтому оставалось два варианта — либо успеть к началу ноября, либо отложить запуск до января.
В итоге, оценив то количество задач, которые успевали сделать к ноябрю, и отбросив из плана те, без которых в момент запуска можно было обойтись, мы решили, что должны успеть в текущем году. Среди крупных блоков, которые отложили, оказались «История изменений» и «Ролевая модель пользователей». Взять в работу только самое нужное нам помогла та самая декомпозиция.
Первоочередные задачи с небольшим запасом легли на диаграмму Монте-Карло. После этого стало понятно, что есть возможность двигаться к внедрению в начале ноября. И в итоге этот план сработал.
Команда
Основой и фундаментом, на котором строятся описанные подходы, является команда. Над PIM трудился и продолжает трудиться сплоченный и профессиональный коллектив. И это не просто дежурные слова, а серьёзный фактор успеха. Высокое качество кода и дизайна, анализа и тестирования напрямую конвертируется в качество продукта.
Большую роль в нашей работе играют и отлично налаженные связи в команде. Они позволяют корректировать и настраивать те процессы, которые описаны выше. Слаживание произошло не одномоментно. В первые месяцы во время ретроспектив поднималось много вопросов и мы старались настраивать наши активности в соответствии с возникающими потребностями.
По прошествии времени видно, что практически одинаковый подход к разработке в разных командах всё-таки отличается в деталях. Важно найти такой порядок, который оптимален на конкретном проекте, с учётом специфик. Здесь сложно привести конкретные примеры, так как процесс непростой. Но можно утверждать, что и ретроспективы, и груминги одновременно помогли нам в этом и улучшились за счёт улучшения связи. На их эффективность сильно влияет мастерство и сплоченность команды, так как они предполагают активные коммуникации и высокую вовлёченность.
Технические решения
Без некоторых технических решений, использованных на проекте, запуск в обозначенный срок вряд ли бы случился. Опишу некоторые из тех, что сыграли важную роль:
- В первую очередь, это продуманный CI, при каждом коммите включающий в себя запуск тестов, проверку покрытия и анализ качества кода при помощи SonarQube. В этом пункте нет ничего оригинального, но тем не менее, он необходим и на длинной дистанции экономит много времени.
- Использование инструмента Helm, чтобы хранить всю конфигурацию, необходимую для развёртывания в Kubernetes внутри приложения. Это тоже сэкономило много времени, так как развёртывание на новом стенде требовало всего лишь добавления нового конфигурационного файла в проект.
- Удачным решением на уровне БД стал выбор схемы хранения товаров и категорий в виде jsonb, в качестве альтернативы привычному EAV-паттерну. Поскольку PIM в большинстве случаев используется на чтение, такой подход, при котором информация хранится в одной таблице, оказался полностью оправдан. И нам повезло, что мы к этому пришли в самом начале разработки. Часть логики, связанная с обновлениями и удалениями, которую берёт на себя БД при EAV-подходе, пришлось бы реализовывать в самом приложении. А здесь сильно помогли возможности Postres, которые он предоставляет при работе с jsonb.
При разработке фронтенд-части:
- Использование @reduxjs/toolkit/query позволило сократить количество кода, необходимое для написания многих фичей, не потеряв при этом в возможностях и UX.
- Использование react-hook-form позволило гибко компоновать и настраивать формы, которых у нас достаточно много.
- UI kit с большим количеством компонентов позволил абстрагироваться от вёрстки, сконцетрировавшись на требованиях.
- Собственный аналог Data Grid сильно упростил создание листингов.
В PIM, как и в других разрабатываемых у нас системах, использовался ELK-стек (Elasticsearch, Logstash, Kibana), который помогает анализировать собираемую при работе приложения информацию. Помимо этого, мы мониторили нагрузку и использование ресурсов с помощью Grafana.
На проекте PIM получилось удачно применить сочетание этих двух подходов — быстро настроить мониторинг и оповещения в Grafana с использованием данных из Elastic. Это дало возможность моментально создавать нужные диаграммы, опираясь на данные из логов. И, в свою очередь, помогло в кратчайшие сроки проанализировать и устранить все ошибки, которые обычно сопровождают первый вывод системы в промышленную эксплуатацию, а также моментально реагировать на возникающие инциденты и сбои в дальнейшем.
Итог, который мог быть содержанием этой статьи
- Нам очень помог профессионализм собранной команды
- Пожалуй, второе место занимает фокус на бизнес-целях, которые строятся на клиентской пользе
- Регулярные груминги и ретроспективы помогают с планированием и упрощают выводы
- Декомпозиция сыграла далеко не последнюю роль не только перед запуском
- Работа с метриками помогает нам в расстановке приоритетов
- Прогнозирование по методу Монте-Карло помогает нам точнее оценивать свои потребности и реалистично соотносить их с ресурсами
- Набор удачных технических решений помогает собирать всё в кучу и не терять ничего важного
Совокупность этих факторов помогла запустить PIM быстрее и помогает развивать продукт.